eBPF: User-Defined Codes in Kernel
Published:
eBPF allows user-defined codes to run safelly in Linux kernel, opening new opportunities for “exo-kernel”.
Motivation
Customize kernel before eBPF
Before eBPF, it is hard to customize the kernel for different applications. For example, to implement different file system policies, one might need to change the source code of the kernel, recompile it and install it, which requires much efforts and is hard to maintain.
Another option is the kernel module. It allows to load and unload new kernel functionalities without rebooting the kernel. An example is the Nvidia Open GPU Kernel Module. Usually, the kernel module is orthogonal to the existing kernel codes (?) and complex to maintain.
In many use cases, the application may prefer customizing the policy or a small portion of the algorithm which is competible with the existing kernel. Moreover, this piece of codes should be more efficient than running in the user space. eBPF is the suitable option for this purpose.
Revolutionary applications using eBPF
Here is a list of applications using eBPF:
More examples can be found on ebpf.io.
eBPF Tracing
eBPF tracing tools include the BCC and bpftrace. The following figure shows some existing eBPF tracing tools:
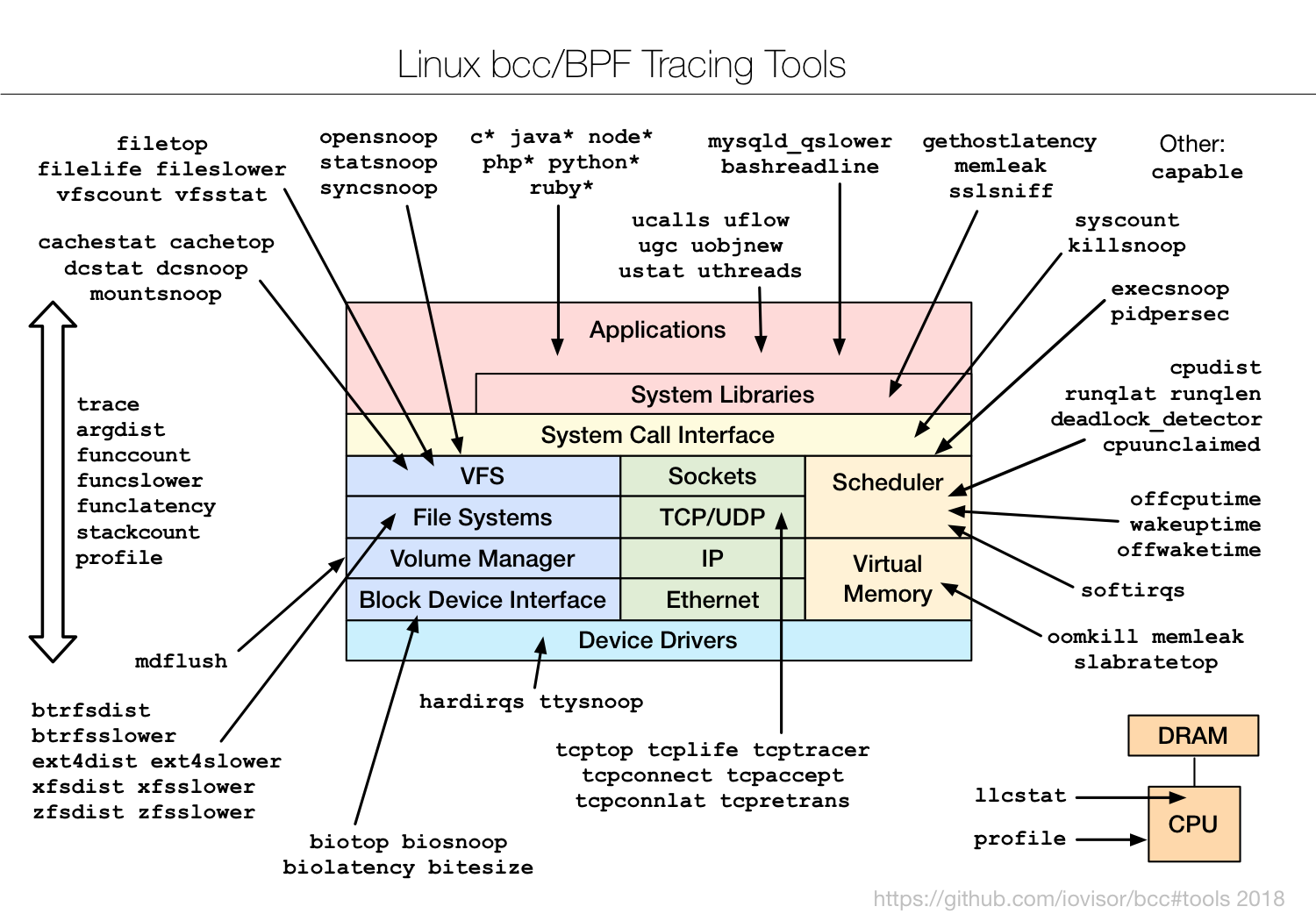
The underlying mechanism relies on tracepoints like the kprobe. Kprobe can register and unregister interrupt handler for most instructions and a trap is fired when the specific instruction hits. This should be the related Linux commit that enables the feature to call an eBPF program from kprobe Merge branch ‘perf-core-for-linus’ v4.1.
XDP: Express Data Path
XDP processes the network packets from the TCP/IP stack, executes eBPF functions and augments the pre-stack actions like filtering. It does not bypass the kernel but instead push the workloads lower. The related patch commit on GitHub is in v4.8 in 2016.
The simplest eBPF function looks like the following:
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
SEC("xdp_drop")
int xdp_drop_prog(struct xdp_md *ctx)
{
return XDP_DROP;
}
char _license[] SEC("license") = "GPL";
The kernel will determine the next steps based on the returned value of xdp_drop_prog.
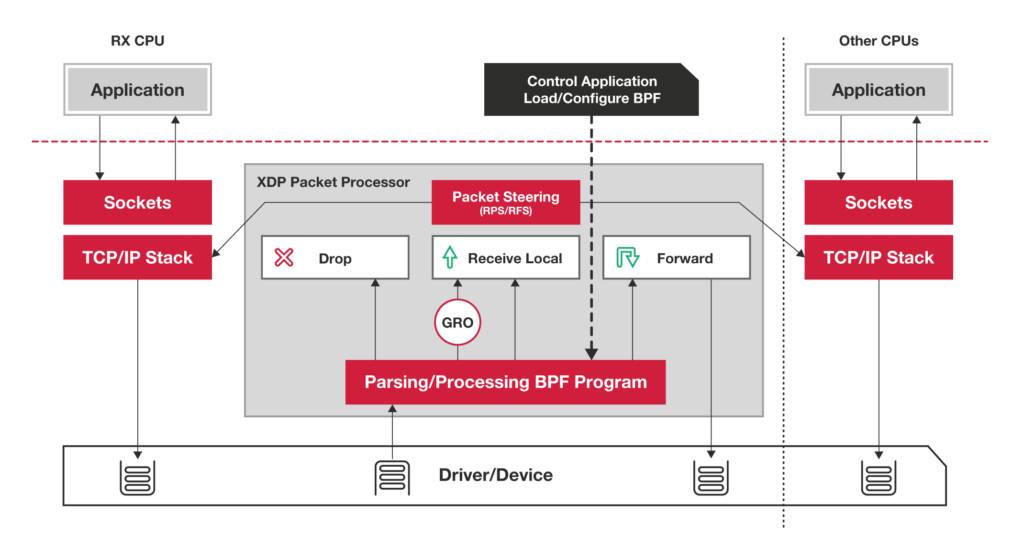
Links:
Katran: Layer 4 Load Balancing
Katran uses XDP to forward network packets. In Facebook, the distributed network uses a virtual IP address (VIP). Packets destined to the VIP are then distributed among the backend servers. The forwarding is handled in the L4 layer (transport layer TCP) instead of the application layer.
Before XDP, the first generation uses IPVS, a kernel module to provide L4 load balancing. For some reason (?), it requires the LB and applications reside on different physical machines.
Katran is built on XDP without bypassing the full kernel stack so it can colocate with the applications. As shown in the following figure, the packet only passes the kernel network stack once when it is delivered to the applications. eBPF also provides development and maintenance flexibility.
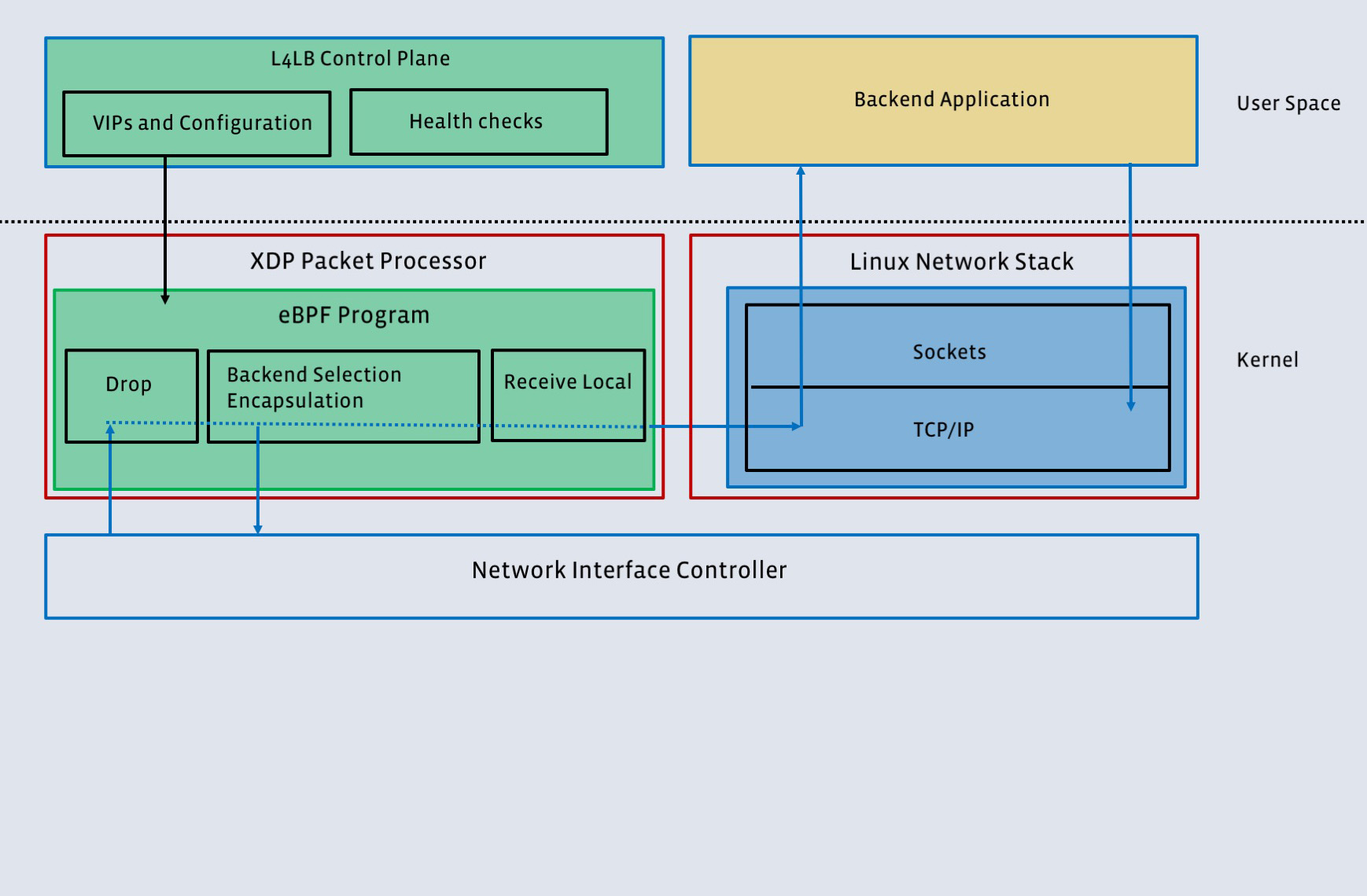
Links:
Cilium: Networking
Cilium is a successful Kubernetes networking and security tool which is based on eBPF. It instruments the network packet processing and uses eBPF to flexibly apply network policies on packets.
The real-world use cases include:
- Kubernetes networking and security in cloud providers.
- Service load balancing.
- …
Links:
XRP: Storage and file system
XRP is a work on OSDI ‘22 which enables applications to define eBPF programs on storage drivers to bypass the overhead of the full kernel stack. It is motivated by the database applications which need to make a sequence of disk reads to walk an on-disk tree. Multiple independent reads repeatly go through the full storage - file system - use application stack and contributes high overhead. Instead, by chaining multiple disk reads into an eBPF program, the driver interrupt can make multiple reads directly and save 50% overhead.
Links:
Bumblebee: eBPF management tool
Bumblebee is a fun project that simplifies eBPF development. It provides the following workflow for an eBPF project:
bee init
# coding
bee build
bee run
The built and packaged images can be shared on a container registry. The Go CLI generates the template files and a user-space monitor program. Bumblebee can be further extended to build the eBPF frameworks :)
Links:
ply: an awk-styled lanaguage for kernel tracing
In many use cases, the common codes for data extraction and aggregation are duplicated across different functions. ply provides an awk-styled language and compiler to directly generate the eBPF programs for simple queries. For example:
// What is the distribution of the returned sizes from read(2)s to the VFS?
ply 'kretprobe:vfs_read { @["size"] = quantize(retval); }'
// From which hosts and ports are we receiving TCP resets?
ply 'tracepoint:tcp/tcp_receive_reset {
printf("saddr:%v port:%v->%v\n",
data->saddr, data->sport, data->dport);
}'
Therefore, this is a useful tool for an early observation.
The code is written in C without a developer’s documentation, so understanding its implementation and contributing to it is hard.
Links:
Parca: Continuous Profiling
Parca is a full-stack solution for Linux continuous profiling. The Parca-agent attaches eBPF programs using perf_event_open syscall to cgroups’ perf events. It collects CPU usage in 19Hz and sends to the server every 10 seconds. The server has a nice UI to render the pprof format data and support simple queries.
It is an interesting and complete project. Maybe it is easy to extend to other resource monitoring like memory.
Links:
Implementations and Usages
Calling an eBPF program in Linux kernel is by using BPF_PROG_RUN. Part of the example code in XRP in file drivers/nvme/host/pci.c is shown as follows:
ebpf_context.data = page_address(bio_page(req->bio));
ebpf_context.scratch = page_address(req->bio->xrp_scratch_page);
ebpf_start = ktime_get();
ebpf_prog = req->bio->xrp_bpf_prog;
ebpf_return = BPF_PROG_RUN(ebpf_prog, &ebpf_context);
if (ebpf_return == EINVAL) {
printk("nvme_handle_cqe: ebpf search failed\n");
} else if (ebpf_return != 0) {
printk("nvme_handle_cqe: ebpf search unknown error %d\n", ebpf_return);
}
atomic_long_add(ktime_sub(ktime_get(), ebpf_start), &xrp_ebpf_time);
atomic_long_inc(&xrp_ebpf_count);
Note that to enable new eBPF calls from the kernel, the developer is required modify the kernel specifically. For example, to check if an eBPF program is registered. If yes, execute it; otherwise, fall back to the default kernel code.
Here are some useful links: